LIME for images explanations are extremely dependent on the choice of tiling. Tiling is one inductive assumption of LIME but it is hidden from the end user.
I know I’m late to the party, but here we go. I was recently asked to say something about philosophical problems in XAI and LIME is an obvious victim for philosophical scrutiny because its mode of operation is quite easy. As far as I am aware what I am going to point out has only been touched upon by Zach Lipton in one sentence in his Mythos of Model Interpretability but has been otherwise ignored by the philosophical community.

If we let InceptionV3 classify the picture above these are the top 5 classifications with their probabilities:
| lemon | orange | strawberry | banana | hip |
| 0.7 | 0.15 | 0.008 | 0.003 | 0.003 |
Never mind that the image actually shows a lime.
Let’s say we wonder which parts of the image contributed the most to its classification as lemon. LIME is a method to do this. For an accessible introduction you can read this article by the developers of LIME.
It basically does the following:
- Segment image (this gives a tiling, every tile is called a superpixel)
- Generate a “perturbed” image by randomly blacking out some superpixels
- Use InceptionV3 to classify the perturbed image, store the probability of it’s being a lemon
- Iterate 2. and 3. and to a linear regression on the probabilities
- Output the most important superpixels according to the linear regression – the resulting picture is called “the explanation”
Okay, let us take inventory. We now have a picture, “the explanation”, which contains the most relevant superpixels that lead to our image being classified as a lemon.
But it is obvious that “the explanations” are very sensitive to the choice of tiling. LIME uses an automated segmentation method called quickshift per default, but this can easily be changed to every segmenter skimage offers. One could even use a simple grid segmentation. Below are examples of different segmentations and the resulting “explanations” one gets from LIME. They differ quite substantially. In fact from the LIME point of view all are different explanations! Which is the correct one?

Grid Tiling
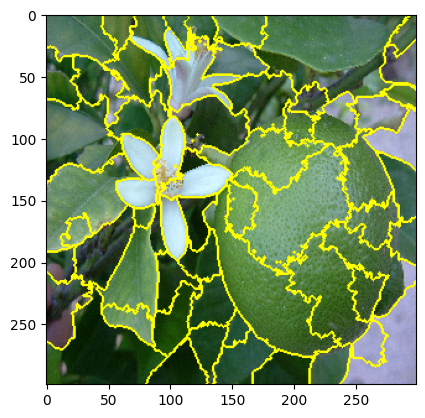

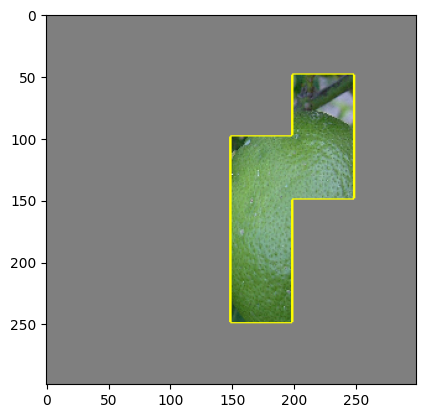
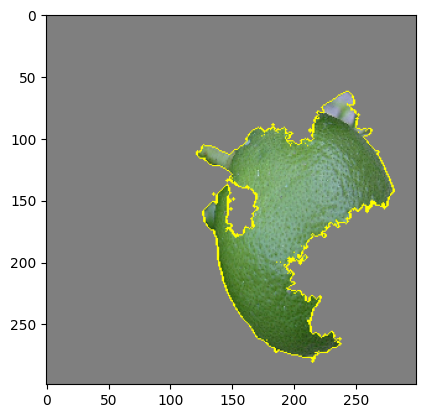
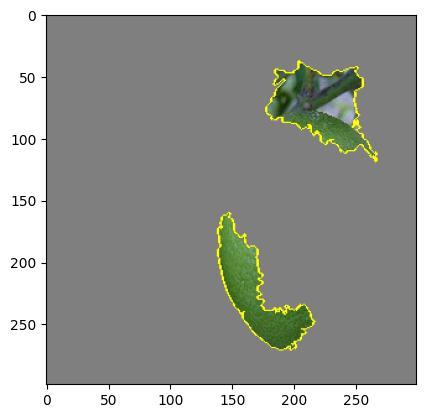
While there has been some work on theoretical guarantees for the linear regression part of LIME, no guarantees can be given for the segmentation part. This is neither discussed in the original LIME paper, nor in the succeeding theoretical analyses. But to know whether a LIME explanation is correct we need to know if the segmentation picks out the explanatory relevant features of the image. If we do this automatically, let’s say using one of skimage’s segmentation methods, we have to count on the method’s inductive assumptions tracking our explanatory interests. But the method doesn’t know our explanatory interests – so it is bound to fail sometimes. And we don’t even know how often it will fail.